Acquisition Motivation
Responding to ASIC Challenges in the Inference Era: How NVIDIA Plans to Stay Competitive
NVIDIA’s current revenue structure remains heavily reliant on GPU shipment growth. Traditionally, the market has depended on NVIDIA GPUs for both AI model training and inference, allowing the company to rapidly scale with the AI boom. However, market sentiment is shifting. As the AI industry moves from an infrastructure-building phase into a phase of real-world deployment, the growth in training demand may begin to slow. In contrast, large-scale commercialization of AI could see inference computing power become the next major growth engine. This shift puts NVIDIA’s general-purpose GPUs in direct competition with more efficient ASICs, potentially affecting both the company’s future revenue streams and its market share.
Take Google’s TPU for example: to support general computing, GPUs include a significant amount of circuitry not needed for AI matrix operations. This leads to larger chip size, increased leakage current, and higher unit costs. In contrast, TPUs are inference-specific ASICs that eliminate unnecessary circuits and use systolic arrays to optimize matrix multiplications—reducing memory access and boosting computing density. Additionally, on the energy side, the power efficiency per watt of GPUs is declining, with cooling and power delivery already accounting for over 30% of total cost of ownership (TCO). TPUs, with their simpler architecture, can offer 2–3x better energy efficiency per watt than traditional GPUs. This makes TPUs more suitable in power-constrained data centers.
Moreover, while large-scale model training can involve tens of thousands of GPUs, NVIDIA’s NVLink and Ethernet-based infrastructure can face latency and power inefficiency issues at extreme scale. Google’s TPUs use Optical Circuit Switching (OCS) for interconnect, enabling low-latency, high-throughput connections among over 100,000 chips without traditional switches. Google's full-stack control—spanning models (Gemini), frameworks (JAX, XLA), compilers, network topology, and data center scheduling—shows a high degree of vertical integration. Meanwhile, other tech giants such as Meta and Anthropic have started exploring alternatives to NVIDIA, indicating that the company’s longstanding competitive moat in AI inference is under increasing pressure. Against this backdrop, NVIDIA must prove the irreplaceability of its products and ecosystem in the inference era to sustain its leadership position.
Systolic Array A systolic array is a chip design that arranges many small processing units like an assembly line to perform matrix operations quickly and efficiently—critical for AI workloads. GPUs, originally designed for flexible use across graphics rendering, ray tracing, and scientific computing, are not optimized for this fixed-flow architecture. ASICs, on the other hand, benefit from custom designs like systolic arrays that maximize efficiency and inference speed.
LPU’s Competitive Edge in the Inference Market
| LPU (Groq) | GPU (NVIDIA) | TPU (Google) | |
|---|---|---|---|
| Primary Function | AI inference (especially LLMs) | General-purpose parallel computing for training & inference | AI/ML acceleration for training & inference |
| Core Architecture | Deterministic execution with programmable flows | CUDA cores + Tensor Cores | Matrix multiplication units (MXUs) |
Founded in 2016, Groq was established by Jonathan Ross, a former senior executive on Google’s chip team and an early TPU contributor. Rather than follow the GPU-style general parallelism route, Groq designed an architecture focused on low latency, predictable execution, and extreme inference efficiency. This philosophy is closely aligned with TPUs but diverges significantly from NVIDIA’s traditional GPU path. Groq developed a new chip called the LPU (Language Processing Unit), optimized at the hardware level for LLM inference.
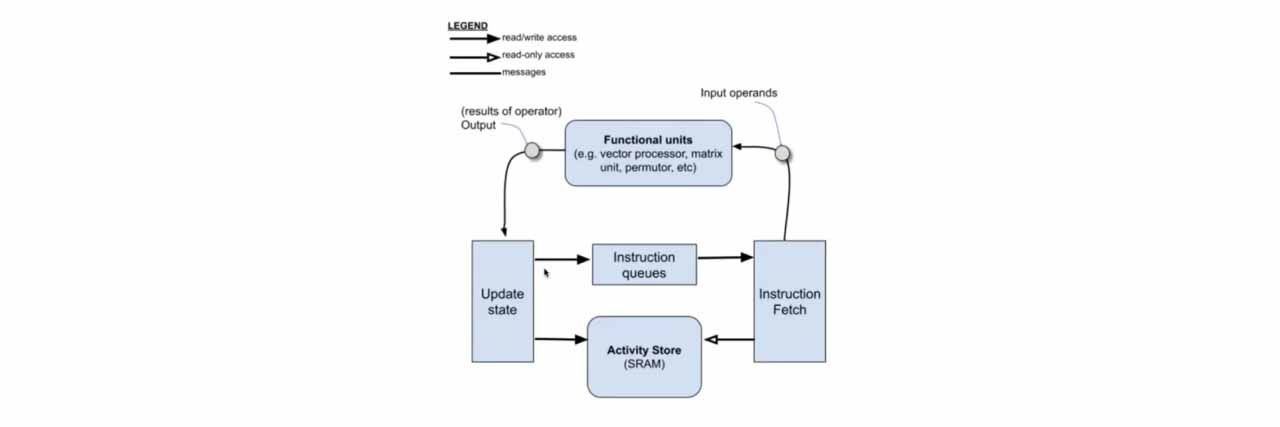
Traditional chip architectures consist of multiple independent cores—each with its own compute, memory, and control logic. Data must frequently hop between cores, creating complex paths and unpredictable latency. Groq’s design disaggregates these functions by segmenting the chip into functional regions—for example, separate zones for data storage and vector computation. This allows data to flow faster across these zones. The LPU’s philosophy is to simplify hardware and rely on powerful compiler orchestration, eliminating hardware logic like branch prediction, cache management, and arbiters. Nearly all transistors are devoted to arithmetic operations.
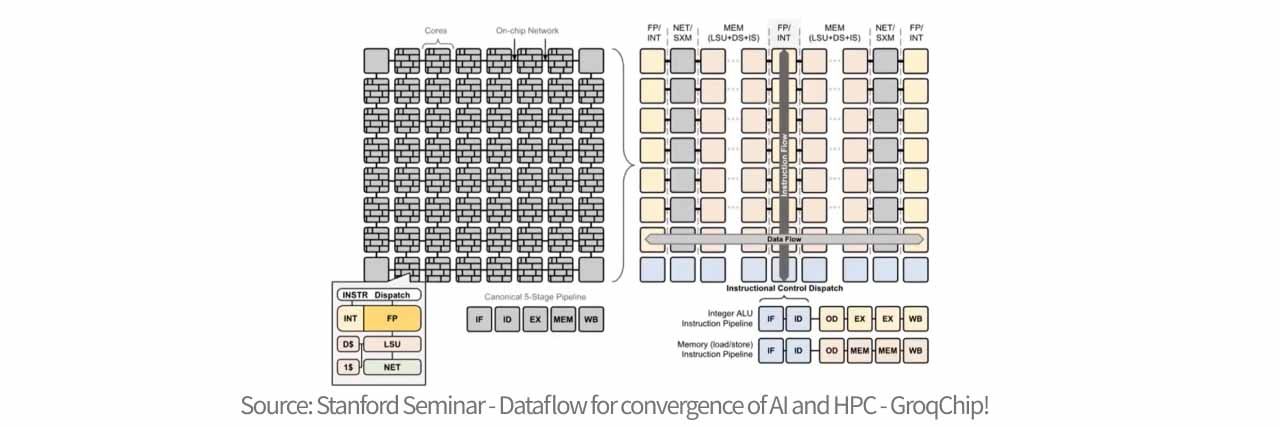
The LPU’s speed advantage comes from its deterministic latency architecture. Unlike traditional GPUs that use complex schedulers, branch prediction, and multi-layer caches (which add latency and unpredictability), the LPU gives full control to the compiler, which pre-schedules every data flow and compute cycle down to the nanosecond. Hardware-wise, the LPU uses on-chip SRAM instead of external DRAM. Its memory architecture includes 88 independent memory slices (MEM slices), each with 8,192 addresses, totaling 230MB. These slices are grouped into quad timing groups and tightly coupled with MXM (matrix operations) and VXM (vector operations) units.
The chip’s interface allows each cycle to read/write 320 bytes from two memory banks. Stream Registers vertically link 64 full bandwidth streams, reaching up to 80TB/s bandwidth—enabling ultra-fast, scheduled data movement with no delays or memory shuttling. This removes latency jitter and redundancy, achieving unprecedented speed and inference performance.
Groq claims that its LPU-based cloud service outperforms NVIDIA AI GPUs in inference speed for models like Llama2 and Mistral, achieving output speeds of around 500 tokens per second. For context, ChatGPT-3.5's public version delivers around 40 tokens per second, meaning LPU can reach up to 10x throughput. In terms of energy, NVIDIA GPUs may consume 10–30 joules per token, while Groq LPUs only use 1–3 joules, signaling a potential order-of-magnitude drop in cost per inference. Moreover, LPU’s integration of high-bandwidth on-chip SRAM (80TB/s vs HBM’s 8TB/s) reduces dependence on external HBM and avoids memory wall delays, allowing token generation speeds of 300–500 tokens/sec.
Synergies & Opportunities from the Acquisition

With AI training now in full swing, the industry’s next focal point is inference. By acquiring Groq’s technology, NVIDIA can quickly incorporate LPU architecture into its AI ecosystem—combining GPU (for training) + LPU (for inference). On the supply side, NVIDIA already controls key bottlenecks—TSMC’s CoWoS packaging and Korean HBM capacity—limiting rivals like TPU. Groq’s LPU, built on 14nm without HBM or CoWoS, avoids competing for cutting-edge capacity. This makes it ideal for fast deployment in the inference window. If a competitor like Google or Meta acquired Groq, it could pose a significant risk to NVIDIA.
To preempt this, on December 24, 2025, NVIDIA acquired a non-exclusive license to Groq’s core AI inference technology for $20 billion. In this transaction:
- NVIDIA gains rights to Groq’s core assets and IP, excluding GroqCloud (which remains independent).
- Groq’s founder Jonathan Ross, President Sunny Madra, and key team members join NVIDIA to scale inference innovation.
- Groq remains an independent entity, now led by former CFO Simon Edwards as CEO.
Groq’s latest post-money valuation reached $6.9 billion. Beyond IPO, a strategic investment or acquisition by a cloud or semiconductor firm remains possible. NVIDIA’s licensing deal, paired with talent integration, highlights its strategic focus on inference as the next major frontier.
- While NVIDIA dominates in training and complex inference, the future of AI (e.g., AI doctors, autonomous driving, real-time translation) demands ultra-low latency and predictable response times—areas where NVIDIA has been relatively weaker. With Groq, NVIDIA fills this product gap. Groq’s LPU excels in single-user, low-latency workloads, delivering high token throughput with deterministic latency. If NVIDIA successfully integrates Groq’s SRAM and dataflow design, it could blend GPU flexibility with LPU speed—mitigating the “memory wall” caused by HBM.
- In September 2025, Groq raised $750 million in Series I funding. NVIDIA’s rapid move to finalize this strategic deal reflects strong conviction. Groq’s deterministic, low-latency strengths address structural GPU weaknesses in real-time inference. Adding this capability strengthens NVIDIA’s appeal to enterprise and cloud buyers and may help maintain unit sales and relieve ASP pressure.
- NVIDIA’s GPU inference strategy has been tightly coupled with HBM and CoWoS. As inference workloads grow, this increases BOM cost, supply risk, and dependency on high-end capacity. If Groq’s architecture can be integrated cost-effectively, NVIDIA may shift from "GPU + large HBM" setups to lighter, cheaper, lower-latency inference solutions—cutting unit costs and risk while aligning better with market needs.
Acquisition Risks
Financial Risks
NVIDIA is paying $20 billion in cash. As of Q3 FY25, NVIDIA had $60.6 billion in cash and equivalents, and post-deal would retain over $40 billion—sufficient for operations, R&D, buybacks, and medium-scale acquisitions.
NVIDIA generated $22.1 billion in free cash flow in Q3 FY25 and $23.8 billion in operating cash flow, meaning the entire deal could be funded by one quarter of cash generation, placing no financial strain.
With a conservative debt-to-equity ratio (~0.1) and interest coverage ratio over 400x, NVIDIA has strong solvency and debt service ability. The full-cash deal underscores confidence in financial health. Thus, the real question isn’t whether this creates financial risk—but whether the deal can deliver ROI or competitive gains within a reasonable time.
Technical Risks
- It’s unclear if Groq’s TSP/LPU architecture can be seamlessly integrated into NVIDIA’s software stack and developer ecosystem. If it can’t be absorbed into CUDA, Groq’s role may remain a fallback solution rather than a scalable product.
- Integration may create internal product conflicts, especially in low-latency inference where LPU could cannibalize GPU offerings unless segmentation is clearly defined.
- The non-exclusive nature of the license means Groq can still license to competitors, and NVIDIA may not be the sole or biggest beneficiary.
Feasibility Analysis
Large acquisitions often face regulatory scrutiny. However, this is more of a “quasi-acquisition”: NVIDIA licensed Groq’s key tech and hired its core team, but did not acquire the company outright. GroqCloud remains independent.
Compared to NVIDIA’s failed ARM deal (which triggered regulatory pushback due to ecosystem-critical IP), this non-exclusive, licensing-based structure reduces antitrust concerns and preserves Groq’s role as an independent competitor and supplier.
Notable NVIDIA Acquisitions
| Company | Deal Size (USD) | Valuation Uplift | Strategic Purpose |
|---|---|---|---|
| Groq (2025) | $20B | ~190% | Strengthen inference competitiveness |
| Mellanox (2020) | $7B | ~17% | Foundation for data center/networking |
| Run:ai (2024) | $700M | ~80% | GPU virtualization & pooling |
| PortalPlayer (2006) | $357M | ~19% | Mobile/handheld media chip tech |
| (Failed) ARM (2020–2022) | $40B | NA | AI ecosystem expansion |
Market Impact
LPU Threatens Traditional Inference ASIC Dominance
LPU’s design is fixed and deterministic, a stark contrast to GPUs’ reliance on hardware scheduling to manage unpredictability. Inspired by dataflow architectures, the LPU omits caches, branch prediction, and arbiters—reducing instruction control overhead to under 3%, maximizing space for matrix compute units (MXUs).
Groq’s compiler pre-schedules all data movements per clock cycle, delivering predictable, jitter-free latency. With 230MB of on-chip SRAM and 80 TB/s bandwidth, the LPU can generate thousands of tokens per second—well beyond traditional memory-bound designs. If NVIDIA integrates this into its GPUs or builds new inference-specific chips, it could challenge Broadcom (AVGO) and other ASIC players using its dominance in training and market share.
LPU Reduces Need for CoWoS and HBM
LPU's memory architecture doesn’t rely on HBM, eliminating the need for CoWoS packaging. Traditional AI chips depend on HBM and 2.5D packaging to support bandwidth needs. LPU embeds 230MB of SRAM directly on-chip, showing that efficient dataflow and compiler-driven scheduling can achieve better inference performance without HBM.
In the short term, HBM remains vital due to capacity and cost. A single GPU’s HBM can be 400–900 times larger than LPU SRAM. But SRAM is far more expensive, and LPU’s applicability is currently limited. Future improvements could broaden its use cases.
LPU’s End Applications
LPU’s value lies in its ultra-low latency enabled by simplified hardware. With no asynchronous networking, the compiler schedules all physical links using global time synchronization, making LPU systems function like a “giant single chip.”
This design is ideal for real-time AI applications—from voice assistants and virtual tutors to latency-sensitive areas like high-frequency trading (HFT), where deterministic behavior ensures no jitter. While SRAM limits model size per node, Groq’s Dragonfly topology enables expansion. LPU systems are carving out a unique market niche for millisecond-scale inference needs—distinct from GPU-based systems.
Commentary
NVIDIA’s licensing of Groq’s technology and hiring of its talent may not yield immediate synergy. LPU still has major limitations, such as expensive SRAM and very limited memory capacity—only a fraction of HBM—which constrains broader application.
Still, LPU offers clear technical potential with its fast compute and power efficiency. Groq’s compiler-driven design also adds value. In addition, talent acquisition has become a strategic norm in the AI race, and NVIDIA’s strong cash position makes the $20B deal manageable. The key will be whether NVIDIA can successfully integrate this technology into its platform and product suite for long-term competitive advantage.
